
Given the importance of an organization’s data, IT must understand when to use encryption, replication, or immutability as part of an overall data resiliency plan. If it is lost because of a disaster, stolen by a rogue employee, or locked up by ransomware, the financial and reputational costs to the business are exorbitant. Knowing how and when to employ these tactics is critical to an overall data resiliency strategy.
When to Use Encryption
Encryption doesn’t necessarily protect data from being accessed; it simply ensures that if data is accessed, only those with proper authorization can read it. Therefore, IT should not use encryption as a ransomware deterrent. Encrypting data once does not mean it can’t be re-encrypted by another process. For a ransomware attack to be successful, it doesn’t need to read the organization’s data; it just needs to ensure the organization can’t.
Encryption can occur at three levels within the infrastructure. If the application supports it, it can encrypt data before sending it over the network and to the storage system. The network, either the card or the switch, can also encrypt data as it goes across the network. And either the storage software or the physical drives can encrypt data as they receive it. The downside of encryption is that if the level applying the encryption is compromised, the data is clear for unauthorized access.
The advantage of application-side encryption is that the access key is only given to authenticated application users. Application-level encryption includes operating system or hypervisor encryption, like the type available through VMware VM Encryption. The downside is that many applications don’t provide this capability. Additionally, many customers don’t implement encryption for applications that can implement it because of performance concerns.
Network encryption is essential but only effective while the data is in flight. It must be decrypted before being written to the storage system.
The organization must ensure that it encrypts data while it remains on physical media. Application encryption provides this level of protection because the data stays encrypted from the point of transmission through the actual writing and storing of the data on the media. A few storage software solutions can provide encryption per volume, enabling organizations to encrypt datasets where the application can’t. Self-encrypting drives provide encryption for a situation where the storage software or the application can’t or the organization wants a blanket approach to data encryption.
When to Use Encryption at the Application Level
If it supports it, application encryption is the most effective means of encryption because it prevents outside access from anything that is not explicitly authorized through the application. There are, however, some negatives to application-level encryption. First, the advantage that all access must come through that application is also a disadvantage. It can make sharing the data with external processes like reporting and analytics engines more difficult. Application encryption will also negatively impact performance, so the application server hardware may need to be more powerful. Application encryption may also render technologies like deduplication useless. Still, the cost of media (flash and HDDs) is so inexpensive now that the payback on the technology isn’t worth the other negative drawbacks.
Finally, application encryption is not universal but specific to that application. Most organizations support dozens of applications and various use cases. Managing the encryption settings on these various applications is confusing, and there is still the problem of some applications or use cases not providing data encryption.
IT should use application-side encryption when possible, especially if the application’s data is critical to the organization or if there is one predominant application in the environment. Organizations should consider combining that encryption with either storage software or media encryption to provide an extra layer of security.
When to Use Encryption in the Network
IT should use network encryption for data transmission across a long-haul network connection. While deploying replication within the data center can further secure data, it is most exposed during a longer transmission. The replication process, either in the application or the storage software, should provide this functionality. It is important to remember that these processes will almost always decrypt data before writing it to storage.
When to Use Encryption in Storage
IT should use storage encryption when application encryption isn’t available, or there is concern over software overhead. The organization may also consider it as a means to further secure data. As with application encryption, storage encryption aims to protect data from an attempt to access data externally. If the storage software provides encryption, it can keep departments or customers (in the MSP use case) from accessing data they shouldn’t. They’d need to be authorized by the encrypted volume.
Within a storage system, self-encrypting drives are typically controlled through a single key, fed to it by the storage solution on bootup. The storage solution has to support the creation, provisioning, and management of the keys for each drive. The problem with self-encrypting drives is that once the storage system gives out the key, anything accessing those drives through the storage system has clear access. Self-encrypting drives’ primary advantage is protection during disposal. Using self-encrypting drives, IT can return old or broken drives to the manufacturer for disposal without concern since their content is not readable.
Encryption’s Role in Ransomware Protection
Encryption has almost no role in protecting data before a ransomware attack or helping an organization recover after an attack. IT should use encryption to prevent data theft or accidental access to data by unauthorized parties.
When to use Replication
Most organizations use replication to create an additional copy of their data at a disaster recovery (DR) site. Some organizations also use replication to create a copy locally within the data center in case the production storage system fails.
While most customers want data replication, the cost of the secondary hardware to implement the process often means the organization must go without or only replicate the most critical of workloads. The high costs are because most storage vendors require a system similar to production at the DR site. This requirement means that if the organization implements an all-flash array (AFA) in production, they must also implement an AFA at the DR site using the same vendor to supply both systems.
However, replication, by itself, will not protect the organization from a ransomware attack. If data is encrypted on the primary storage system, a replication process will replicate that encrypted data to the secondary copies. There is also the potential for the malware to instantiate on the disaster recovery site first and encrypt the secondary copy. If the organization is cross-replicating data between the two sites, there is even the potential for the malware to infect the secondary site.
Replication’s Role in Ransomware Recovery
Replication has a role in ransomware recovery but IT must combine it with a technology capable of creating immutable copies of data. Then replication can copy this data to a secondary storage system elsewhere in the data center or to a different storage solution. Then if the storage software can execute an independent snapshot schedule on the secondary system, the customer can create a digital air-gapped copy of data that provides an additional recovery source in case of a successful ransomware attack.
When to Use Immutable Data Copies
The primary purpose of immutable data copies is to protect an organization’s data against a ransomware attack. However, it can also help an organization recover data if a user accidentally deletes or overwrites data. Immutable copies will not protect against theft because the data is still readable. They also will not protect against a storage system or site failure because the software stores immutable copies on the same storage system as production.
A weakness of leveraging immutable copies as part of a ransomware recovery strategy is the inherent weakness of software vendors’ implementation of the technology. Most vendors, who use their snapshot feature to create an immutable copy, require users to manually set the snapshot to immutable, which makes it challenging to manage a high number of snapshots. It is not an automatic process as it should be. This requirement risks data until the snapshot is manually set to immutable. Most storage vendors rely on the old legacy storage I/O stack, limiting the snapshot frequency and retention time. These systems can’t deliver the production-class performance and snapshot granularity required to recover from a ransomware attack.
Immutable Copies’ Role in Ransomware Recovery
Immutable snapshots, if the storage system can execute persistent snapshots (every few minutes) and retain that snapshot indefinitely (weeks or months) without impacting performance, are an excellent defense against a ransomware attack. The IT team should take the extra step of creating a digital airgap, replicating that data to a secondary storage system at a DR site and, if affordable, within the data center.
A Holistic Approach to Encryption, Replication, and Immutability
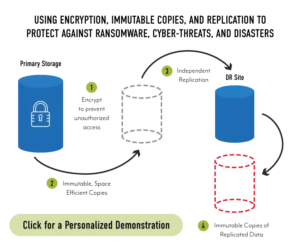
Organizations need to employ encryption, replication, and immutability in tandem, optimally using each capability. Then they need to layer in other capabilities to provide 100% data resiliency. The problem is that many storage systems don’t provide all of these capabilities with a single product, and others limit how deeply IT can use them. StorONE’s modern storage engine is a complete rewrite of storage I/O. It is not dependent on the legacy I/O stack, enabling IT to deploy these capabilities from a single platform and not limit their use because of performance concerns.
The StorONE engine supports application-side encryption. It can also provide encryption at the virtual storage container (VSC) level and supports self-encrypting drives, enabling IT to select the strategy that makes the most sense. That same engine enables cascading replication between multiple sites, and it can replicate to disparate hardware bringing down the cost of disaster recovery infrastructure. Finally, StorONE’s snapshot technology is immutable by default, and IT can set schedules to execute every 30 seconds while retaining those snapshots indefinitely without impacting performance. When implemented together, StorONE’s encryption, replication, and immutability enable IT to defend the organization from rogue employees, theft, natural disasters, and ransomware.
Leveraging Layers of Resiliency
A Data Resiliency Strategy should have multiple layers, and we’ve only highlighted three of those layers in this article. Additional layers include:
- Eliminating the need for a write cache while still delivering high performance
- Redundant storage controllers
- Protection from storage media and enclosure failures.
Join StorONE’s Solutions Architect, James Keating, for our webinar, “The Six Requirements for a Data Resiliency Plan.” During the webinar, he will review the data threat list and provide insight on how to design a multi-level data resiliency plan to ensure continuous data access regardless of the threat the organization faces. Learn what data resiliency features you need and how to implement them properly.


